
译者序
这篇文章是The fastest production-ready image resize out there. Part 1. General optimizations的DeepL机翻+人工复核。如有翻译问题可在评论区指出。其作者Alex Karpinsky系Pillow-SIMD的开发者。
上一篇的翻译在这。
前言
在此前的介绍性文章中,我对图像缩放的挑战进行了全面总结。结果发现这个故事相当长,而且有点半生不熟:它没有包含一行代码。
不过,如果没有前面的总结,就很难谈及具体的优化方法。当然,我们可以将一些技术应用到手头的任何代码中。例如,缓存计算或减少分支。但我认为,如果没有对所处理问题的整体理解,就无法完成某些事情。这就是活人与编译器自动优化的区别。这也是为什么人工优化仍然起着至关重要的作用:编译器处理代码,人类处理问题。编译器无法判断一个数字是否具有足够的随机性,而人类却可以。
让我们回忆一下,我们正在讨论通过Pillow Python库中基于卷积的重采样来优化图像缩放速度。在这篇“通用优化”文章中,我将向大家介绍我几年前实施的更改。这不是一个逐字逐句的故事:我优化了叙述的优化顺序。我还在版本库中创建了一个单独的 2.6.2版本分支,这是我们的起点。
测试
如果你想拥有交互式的体验——不止于阅读,还想运行一些测试,这里有pillow-perf软件仓库。你可以自行安装并运行测试:
1 | Installing packages needed for compiling and testing |
由于Pillow由许多模块组成,无法以增量方式编译,因此我们使用ccache工具加快重复编译的速度。
pillow-perf允许你测试许多不同的操作,但我们对规模特别感兴趣,其中-n 3设置了测试运行的次数。虽然代码的运行速度很慢,但我们还是使用较小的-n数来避免睡着。下面是初始性能的结果,来自commit
bf1df9a:
1 | Operation Time Bandwidth |
大家可能还记得,测试显示的是 2560×1600 RGB 图像的缩放。
上述结果与2.6版本的官方基准性能有所不同。原因有两个:
- 官方基准测试使用的是64位Ubuntu 16.04和GCC 5.3,而我在本文中使用的是32位Ubuntu 14.04和GCC 4.8。读完这篇文章,你就会明白我为什么这么做了。
- 在这一系列文章中,我首先提交的是与优化无直接关系但会影响性能的错误修复。
代码结构
我们将要研究的代码的重要部分位于Antialias.c文件中,即ImagingStretch函数。该函数的代码可分为三部分:
1 | // Prelude |
正如我在上一篇文章中强调的,基于卷积的大小调整可以分两次(two passes)进行:第一次是改变图像宽度,第二次是改变图像高度,反之亦然。
ImagingStretch函数在一次调用中处理其中一个维度。在这里,你可以看到每次调整尺寸操作都要调用函数两次。首先是前处理,根据输入参数执行一个或另一个操作。在函数内部,根据处理方向的调整,两次传递看起来都差不多。为简洁起见,下面是其中一个过程的代码:
1 | for (yy = 0; yy < imOut->ysize; yy++) { |
我们可以看到Pillow支持的图片格式分支:单通道8位、灰色阴影;多通道8位、RGB、RGBA、LA、CMYK等;单通道32位和32位浮点运算。我们对多通道8位格式特别感兴趣,因为它是最常见的图像格式。
优化点1:有效利用缓存
虽然我说过这两段步骤看起来很相似,但还是有很大区别的。让我们先看看“垂直”的做法:
1 | for (yy = 0; yy < imOut->ysize; yy++) { |
以及“水平”的做法
1 | for (xx = 0; xx < imOut->xsize; xx++) { |
在垂直处理(vertical pass)过程中,我们会沿列方向遍历结果图像(resulting image),而在水平处理(horizontal pass)过程中,我们沿行遍历。垂直遍历对处理器高速缓存来说是一个严重的问题。嵌入式循环的每一步都会访问一行的起始元素,因此所请求的值与前一步访问的值相距甚远。
这在处理较小尺寸的卷积时是个问题。目前的处理器只能从内存中读取64字节的缓存行。这意味着,当我们卷积的像素小于16个时,从RAM中读取部分数据到缓存是一种浪费。但想象一下,我们将循环倒置。现在,每个卷积的像素都不在下一行,而是当前行的下一个像素。因此,大部分所需的像素都已经在缓存中了。
这种代码组织的第二个不利因素与较长的卷积行有关:在大幅降频的情况下。问题是,相邻卷积的原始像素会有很大的交集,如果这些数据还保留在缓存中,那就再好不过了。但当我们从上到下移动时,缓存中的旧卷积数据会逐渐被新卷积数据取代。因此,在嵌入式循环之后,当下一个外部步骤开始时,缓存中就没有上层行了,它们都被下层行所取代。因此,我们必须再次从 RAM 中读取这些上行数据。而当读取到较低行时,缓存中的所有数据都已被较高行取代。这样就形成了一个循环,缓存中根本没有需要的数据。
为什么会这样呢?在上面的伪代码中,我们可以看到两种情况下的第二行都代表卷积系数的计算。在垂直方向(vertical pass)上,系数只取决于结果图像中某一行的yy值,而在水平方向上,系数则取决于当前列中的xx值(也就是卷积系数取决于目标图像中的坐标[xx,yy])。因此,我们不能简单地将两个循环对调,我们应该在针对xx的循环中计算系数。如果我们在内循环中计算系数,性能就会下降。特别是当我们使用Lanczos滤波器进行计算时——它使用了三角函数。
因此,我们不应该在每一步都计算系数,即使一列中对每个像素的系数都是相同的。不过,我们可以预先计算好所有列的系数,并在内循环中使用它们。下面来实践一下。
分配一行内存用于存放系数:
1 | k = malloc(kmax * sizeof(float)); |
现在,我们实际需要一个由上面的数组组成的矩阵。我们可以通过分配一个平面内存片段并通过寻址模拟两个维度来简化:
1 | kk = malloc(imOut->xsize * kmax * sizeof(float)); |
我们还需要存储xmin和xmax,它们也与xx相关。让我们为它们创建一个数组:
1 | xbounds = malloc(imOut->xsize * 2 * sizeof(float)); |
此外,在循环内部,ww的值用于归一化,即\(ww = 1 / \sum{k}\)。我们根本不需要存储它。相反,我们可以对系数本身进行归一化处理,而不是对卷积结果进行归一化处理。因此,在计算出系数后,我们会再次遍历这些系数,用每个值除以系数总和。这样,所有系数之和就变成了\(1.0\):
1 | k = &kk[xx * kmax]; |
最后,我们可以将流程“旋转90度”:
1 | // Calculating the coefficients |
以下是我们得到的性能结果,commit d35755c:
1 | Operation Time Bandwidth Improvement |
第四列显示了性能改进情况。
优化点2:更高效的取值截断
在代码的某些部分,我们可以看到这样的结构:
1 | if (ss < 0.5) |
该代码段用于将像素值限制在[0, 255]的8位无符号整型范围内,以防计算结果溢出。出现这种情况的原因是,所有正卷积系数之和可能大于1,而所有负卷积系数之和可能小于0。因此,我们有时会偶然发现溢出。溢出是对锐利的亮度梯度进行补偿的结果,并不是错误。
让我们来看看代码。有一个输入变量ss和一个输出imOut -> image[yy]。输出在多个地方被赋值。这里的问题是,我们在比较浮点数,而将数值转换为整数再进行比较会更有效。因此,这就是函数:
1 | static inline UINT8 |
这次优化也提升了性能,这次是较平缓的提升,commit 54d3b9d:
1 | Operation Time Bandwidth Improvement |
正如您所看到的,这种优化对窗口较小、输出分辨率较大的滤镜效果更好,只有320×200双线性滤镜例外。我没有研究为什么会出现这种情况。这是合理的,滤镜窗口越小,最终分辨率越大,我们的值约束方法对整体性能的贡献就越大。
优化点3:循环展开
如果我们再次查看水平处理(horizontal pass)的代码,就会发现有四个内循环:
1 | for (yy = 0; yy < imOut->ysize; yy++) { |
我们正在遍历输出图像的每一行和每一列:准确地说,是每一个像素。嵌入式循环的目的是遍历输入图像中需要卷积的每个像素。那么变量b呢?它的作用是遍历图像的通道(比如RGB就是三个通道)。很明显,由于Pillow表示图像的方式,通道的数量是相当固定的,不会超过四个。
因此,有四种可能的情况,分别对应1-4通道图像。然后,我们添加分支以在不同模式间切换。下面是最常见的三通道图像的代码:
1 | for (xx = 0; xx < imOut->xsize; xx++) { |
(这里我有个疑惑,明明是三通道图像,为何会以4字节为步长遍历源图像?我猜测Pillow统一使用了四通道表示,即把RBG图像看作屏蔽了A通道的RGBA格式,好处是更方便SIMD处理,坏处是内存消耗增加。希望懂Pillow的大佬能在评论区解答一下疑惑。我后续也会阅读一下源码看看猜得对不对。)
我们还可以更进一步,把分支再拆开,拆成 xx 的循环:
1 | if (imIn->bands == 4) { |
以下是我们在commit 95a9e30中获得的性能改进:
1 | Operation Time Bandwidth Improvement |
垂直方向上也可以找到类似的代码。以下是性能较差的初版代码:
1 | for (xx = 0; xx < imOut->xsize*4; xx++) { |
这里没有基于通道的迭代。相反,无论图像中有多少通道,xx都会遍历所有的四个通道(RGB不是三个通道吗?为什么这里会提到四个通道?如果读者对这一点有疑问可以看看我前面针对通道数问题给出的译注)。注释中的FIXME与此修复相关。我们也在做同样的事情:添加分支语句以根据输入图像的通道数切换实现。代码可以在commit f227c35中找到,以下是结果:
1 | Operation Time Bandwidth Improvement |
我想强调的是,水平处理的优化为图像缩小提供了更好的性能,而垂直处理则为放大提供了更好的性能。
优化点4:避免循环中的类型转换
1 | for (y = (int) ymin; y < (int) ymax; y++) { |
如果我们看一下嵌入式循环,就会发现ymin和ymax被声明为浮点数。但是,每一步都会将它们转换为整数。此外,在循环外部,当变量被赋值时,会使用函数floor和ceil。因此,尽管变量最初声明为浮点数,但分配给它们的每个值都是整数。同样的概念也适用于xmin和xmax。我们来修改一下,看看性能如何,commit
57e8925:
优化点5:cvtsi2ss指令中的数据假依赖
我承认我对结果很满意。我成功地将代码的运行速度提高了2.5倍,而且你不必使用更好的硬件或类似的东西就能获得提升:相同CPU的相同内核数。唯一的要求是将Pillow升级到2.7版本。
更新发布还有一段时间,我想在服务器上测试一下新代码。我克隆了代码并进行了编译,一开始,我甚至感觉自己弄错了什么:
1 | Operation Time Bandwidth |
什么?
一切都和优化前一样。我把所有内容都重新检查了十遍,并通过打印来检查是否运行了正确的代码。这并不是Pillow或环境的副作用:即使是30行的小代码片段,也能轻松重现问题。
我在StackOverflow上发布了一个问题,最终发现了这样一个规律:如果使用64位平台的GCC编译,代码运行速度会很慢。这就是我的笔记本电脑(32位)和我克隆代码的服务器(64位)上运行的系统之间的区别。
摩尔说,我没有疯,这是编译器中的一个真正的错误。此外,他们在GCC 4.9中修复了这个错误,但GCC 4.8包含在当前的Ubuntu 14.04 LTS发行版中。也就是说,GCC 4.8很可能已被该库的大多数用户安装。忽略这一点是不切实际的:如果优化在大多数情况下都不起作用,用户又怎么能从优化中受益呢?
我在StackOverflow上更新了问题,并发了一条推文。Vyacheslav Egorov是前V8引擎开发人员,也是一位优化天才,他就是这样来帮助我的。
要了解这个问题,我们需要深入研究CPU的历史及其当前架构。在很久以前,x86处理器并不能处理浮点数,而是由支持x87指令集的协处理器来处理。协处理器与CPU执行同一线程的指令,但作为独立设备安装在主板上。然后,协处理器被内置到中央处理器中,并在物理上组成一个设备。随后,在奔腾III CPU中,英特尔推出了一组名为SSE(流SIMD扩展)的指令。顺便提一下,本系列的第三篇文章将专门讨论SIMD指令。尽管名称如此,但SSE不仅包含处理浮点数的SIMD指令,还包含用于标量计算的相应指令。也就是说,SSE包含一组与x87指令集相同但编码和行为不同的指令。
然而,编译器并没有急于为浮点运算生成SSE代码,而是继续使用旧的 x87 集。毕竟,在 x87 数据集存在了几十年的情况下,CPU中SSE的存在无法得到保证。64位CPU模式问世后,情况发生了变化。在这种模式下,SSE2指令集成为强制性指令集。因此,如果你为x86编写64位程序,至少可以使用SSE2指令集。编译器就是利用这一点:它们为64位模式下的浮点运算生成SSE指令。同样,我说的是普通标量计算,不涉及矢量化。
很久以前,处理器确实“执行”过指令。它们会获取指令、解码指令、执行指令的内容,并把结果放到应该放的地方。这些都是更聪明的做法。现代处理器更聪明、更复杂:它们由数十个不同的子系统组成。在单个内核上,不需要任何并行处理,CPU在一个时钟周期内执行多条指令。不同的指令在不同的阶段执行:一些指令正在解码,另一些指令从高速缓存中获取数据,还有一些指令被传送到运算块。每个处理器子系统处理其部分指令。这就是所谓的CPU流水线。
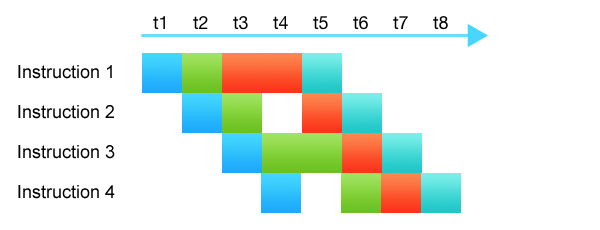
图中的颜色表示不同的CPU子系统。尽管指令的执行需要4-5个周期,但由于流水线的存在,每个时钟周期都可以启动一条指令,同时终止另一条指令。
流水线的工作效率越高,填充越均匀,闲置的子系统就越少。甚至有CPU子系统可以规划最佳的流水线填充:它们可以交换、拆分或合并指令。
导致CPU流水线性能低下的原因之一是数据依赖性。当某些指令需要另一条指令的输出才能执行时,许多处理器子系统就会闲置,等待这些输出。
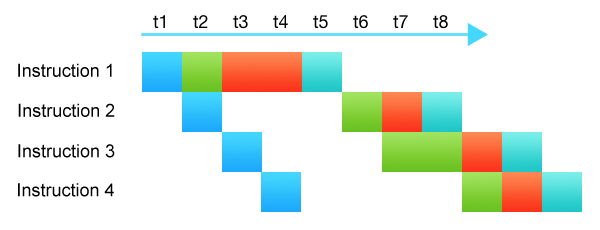
如上图所示,指令二正在等待指令一完成。大多数子系统处于空闲状态。这就减慢了整个指令链的执行速度。
有了这些信息,现在让我们看看将整数转换为浮点数的指令的伪代码:
1 | Instruction: cvtsi2ss xmm, r32 |
结果只写入了dst的低32位。但实际情况并非如此。还有寄存器a的32-127位被传送到dst寄存器,用于保护高位。
查看该指令的签名,我们会发现它只处理一个xmm寄存器。这意味着dst和a都与同一个寄存器有关:这就导致了数据依赖性。该指令的编写方式确保了高阶位的安全,因此,我们需要等待所有其他对寄存器进行操作的结果,才能执行该指令。
但问题是,我们并没有使用任何高位,我们感兴趣的是低位32位浮点数。我们不关心高位,因此高位不会影响我们的结果。这就是所谓的虚假数据依赖。
幸运的是,我们可以打破这种依赖关系。在执行cvtsi2ss转换指令之前,编译器应通过xorps执行寄存器清理。我不能说这是一个直观甚至合乎逻辑的修复。很有可能,这不是一个修复,而是解码器层面的一个黑客程序,它用一些内部指令取代了xorps + cvtsi2ss,伪代码如下:
1 | dst[31:0] := Convert_Int32_To_FP32(b[31:0]) |
GCC 4.8的修复程序相当难看;它由汇编程序和检查是否可以应用修复程序的预处理器代码组成。我不会在这里展示代码。不过,您可以随时查看commit 81fc88e。这完全修复了64位代码。下面是它对服务器机器性能的影响:
1 | Operation Time Bandwidth |
我在本系列中描述的情况非常常见。几乎所有程序中都有将整数转换为浮点数然后进行计算的代码。例如,ImageMagick也是这种情况:使用GCC 4.9编译的64位版本比使用以前GCC版本编译的版本快40%。在我看来,这是SSE的一个严重缺陷。
简短的总结
这就是我们如何在不改变方法的情况下实现 2.5 倍的平均改进:通过使用通用优化。在下一篇文章中,我将介绍如何通过实施SIMD技术将结果提高3.5倍。
(貌似这个作者没有写下一篇,寄)