
工具
静态分析、修复与代码格式化
使用Rust实现的针对Python的静态分析与修复工具。一大批双修大神在积极地维护ruff并推进新特性。特点是支持海量规则。截止至本文最后一次更新时,ruff已经可以完全替代isort(对导入包排序)、pylint(静态检查)和black(代码格式化)。并且它的速度快得离谱。
附上本人使用的pyproject.toml配置参数:
1 | [tool.ruff] |
将ruff设置为VSCode Python格式化工具后就可以使用快捷键Ctrl+Shift+F一键格式化了。
并且我还推荐在VSCode中将排序imports(ruff.exceuteOrganizeImports,和isort的功能一致)的快捷键设置为Ctrl+Shift+E,方便一键排序快速治疗强迫症。
包管理
我对包管理工具的体验并不算多,欢迎深度玩家拍砖。更详细的对比可以参考这篇文章。
目前用户较多的现代包管理工具有以下三个,rye、pdm和poetry。
三者的第一个主要区别是,rye不会构建与平台无关的lock文件,而pdm和poetry会。因此rye的lock速度非常快,而pdm和poetry因为要构建各平台通用的lock,速度自然要慢得多。平台无关的lock文件似乎能让用户更好地掌控跨平台开发时的环境一致性,但我感觉这操作意义不大。与其用hash来锁定版本不如充分信任包作者和PyPI源。
第二个区别是,poetry不支持PEP-621 - Storing project metadata in pyproject.toml,即在pyproject.toml中定义所有项目信息。这个issue自从2021年10月提出,到24年3月的第三方PR(截止发稿仍处于测试阶段)开启,整整三年未能得到修复。因此我强烈不推荐使用poetry。
第三个较小的区别是,rye支持纯脚本形式的项目,即项目中不存在一个libabcd那样的包文件夹。只需要在pyproject.toml中配置[tool.rye] virtual = true即可。
第四个较小的区别是,pdm换镜像源非常方便(国人作者深知国内用户痛点),命令行即可搞定。而rye和poetry都需要手动修改配置文件。
我目前更倾向于使用rye,因为它真的是太快了。而且rye内部集成了ruff,二者都是同一家公司在维护,可能更有利于工具链的稳定。
基于CMake的混合语言构建
虽然截止2023年10月该仓库只有97个star,但它绝对是目前最先进的Python混合语言构建工具。
相对于姊妹scikit-build,它完全摒弃了以setup.py为主CMakeLists.txt为辅的思路,转为完全在CMakeLists.txt中定义Py扩展库的构建流程,从而可以为IDE的各种静态分析工具提供更好的兼容性,也更遵从PEP-621 (把所有元数据扔进pyproject.toml) 的思路。
我还为这个工具写了一个demo project。
使用property提供参数提示
传递环境参数时尽可能使用自定义的Config容器而不是让字典到处乱飞,例如:
1 | class DatasetConfig(object): |
在VSCode中,将鼠标悬停在通过字典传参的angle_num上时,我们无法获得任何关于angle_num的信息。
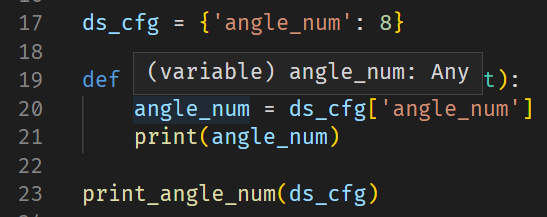
而通过自定义DatasetConfig,我们利用property为类成员变量angle_num添加了类型提示、文档以及只读保护。看看它的鼠标悬停效果。
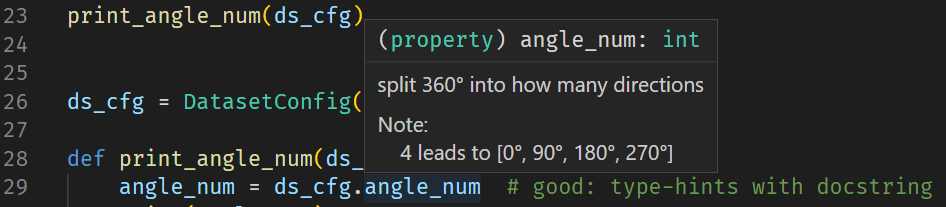
类型提示,意味着你不需要像这样angle_num: int = ds_cfg['angle_num']在每次取用参数时都手动添加类型提示
文档,意味着只要类型提示可用,任何人在任何位置使用DatasetConfig.angle_num时都可以立刻看懂这个参数的具体含义,减少用户翻阅文档或者看源码做阅读理解的频率。
只读保护,通过空置property.setter,我们有效避免了这个与数据集高度绑定的参数在运行时被意外修改。
类属性也天然支持IDE的自动补全功能:

后续在修改angle_num的名称时,我们也不再需要战战兢兢地做全局搜索,只需要使用IDE自带的变量重命名功能即可。
推荐在一部分框架被敲定之后就尽快将参数字典固化成自定义的Config类。这种自定义类也可以通过嵌套字典来提供针对beta模块的灵活性。例如这里我还不太确定要用什么lr_scheduler,就在TrainConfig里嵌了一个带文档和类型提示的的参数字典:
1 | class TrainConfig(object): |
善用继承
在我主刀的Python项目中,继承的唯一作用是允许用户快速了解某个类实现了哪些抽象接口,任何类都不得继承自非抽象类,一切代码复用都使用组合完成。正确的抽象化有诸多好处:用户可以快速判断参数和返回值中复杂类型的兼容性;在复用代码和构建数据管线时有效规避bug;允许使用天马行空的Mock用例构建严苛的测试流程。
在那个先进了(相对Fortran等远古语言)但又不那么先进的C++98时代,为什么很多C++标准库都强调“继承”?除开使用虚函数这一语言特性的需求,我猜测这是为了在派生类中使用和基类一致的内存偏移,以保证二进制兼容性。但时过境迁,飞速提高的硬件性能允许我们在应用层面更多地面向人类而不是机器编程,二进制兼容问题也逐渐成为了库开发者的“专利”,因此“组合”也越来越受到重用。
我认为组合最核心的优势在于,组合可以低成本地避免命名空间的交叉污染。即便发生命名冲突,我们也可以在单一一个类的命名空间中将其解决。例如:
1 | class Config: |
但如果要在继承中实现这一点,只能通过为变量名和函数名添加越来越复杂的前后缀来避免冲突。而一旦发生命名冲突,不仅检查工具不会给出警告,用户还需要沿着继承链查找所有的父级命名空间来规避同名变量,这无疑极大加重了用户的心智负担。例如:
1 | class Config(TrainConfig, EvaluateConfig): |
而且在传递参数时,由于天然的命名空间隔离,组合能更方便地避免状态被过度暴露。比如当我们要传递一个TrainConfig参数给训练函数,当使用组合设计时我们就不必将整个cfg传递进去,而只需要传递一个cfg.train。
Python并不是一门年轻的语言,它的设计范式同样深受继承的影响。本节标题“善用继承”想讨论的就是如何合理利用这种build-in特性,而不是让它成为我们的绊脚石。
Python中,如果class Car继承了class Vehicle,那么我们可以说Car
is a
Vehicle,Car应当实现了Vehicle中定义的所有接口。只有在表示具体类和抽象接口之间的关系时,继承才可以说是没有任何副作用,即抽象基类不会向子类引入额外特性,而仅仅是作为子类的一个接口约束。
在Python中,受到语言限制必须使用继承的场景毕竟还是少数(除了表示抽象接口之外,我目前暂时能想到的只有元编程),其余的大部分使用场景,继承都可以用组合替代实现,那么我们为何不用微小的性能损失来换取“无价”的开发时间呢?
总结一下,如何善用继承?我的建议是只将继承机制用于约束特性,而不是引入特性;只用于阐述类实现了哪些抽象接口,以及通过组合抽象接口来声明更高层次的抽象接口,而不是帮助类去实现接口,以及,代码复用建议完全由组合实现。
使用Protocol抽象化接口
在Python3.6+中,官方建议通过PEP-544中规定的typing.Protocol来声明抽象接口。
例如:
1 | from typing import Protocol |
这里可能有人有疑惑——通过继承abc.ABC并使用装饰器@abc.abstractmethod定义抽象类所实现的抽象与上述使用typing.Portocol的实现方式有何差异?我们先来看下面这个例子:
1 | from abc import abstractmethod, ABC |
它们之间一个直观的区别在于,明确继承一个用户定义的AbsBirdProtocol意味着“必须”实现其中所有的抽象接口,虽然不实现也不会在运行时报错,但静态分析工具会给出警告;而继承一个AbsBirdABC则不必实现所有接口,子类依然可以是抽象类,静态分析工具仅会在用户尝试实例化抽象类BirdABC时抛出警告。
这里需要补充解释一下什么是静态分析。静态,就是运行前的“静止”状态,与运行时的动态相对。这种“静态”不受运行时状态影响。因此Python静态分析与C/C++编译期分析颇为相似。静态分析工具可以利用包中包含的各种静态声明信息来完成静态分析。
将语言服务器Pylance的类型检查功能打开,你就能看到对应的两条警告:
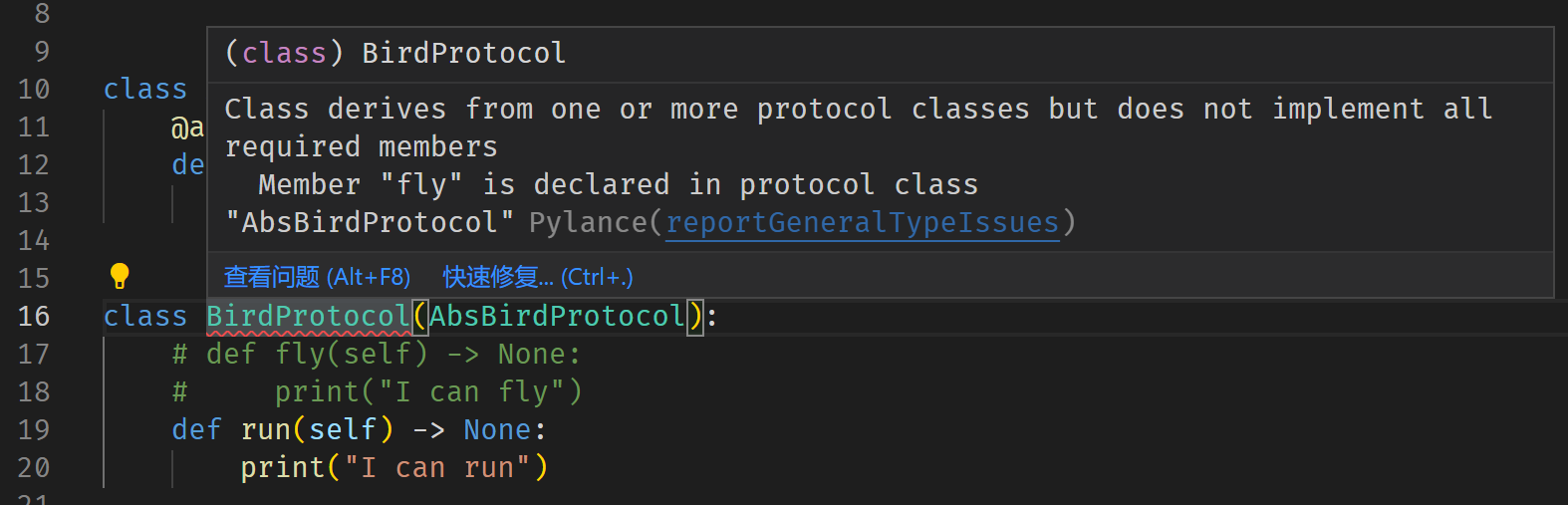
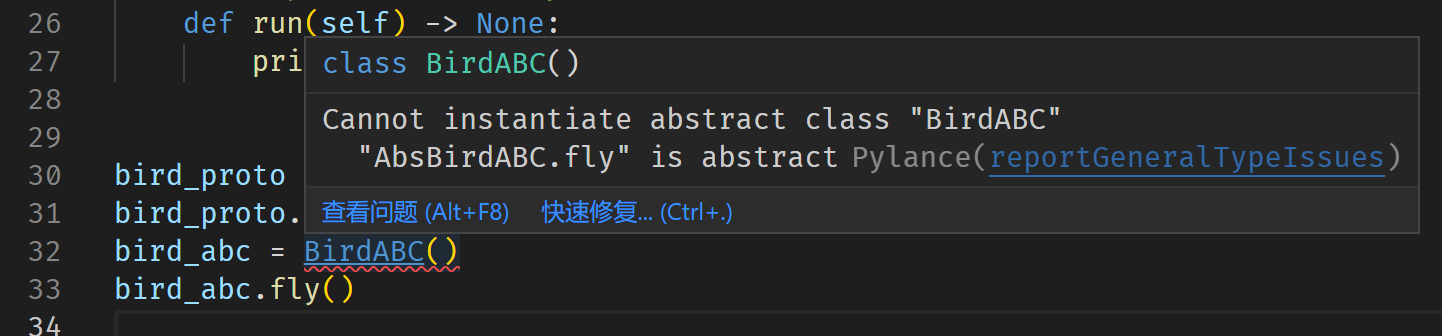
现在设想一下,如果我们编写的库需要将BirdABC暴露给用户,然而出于某种失误BirdABC并没有实现fly方法,进而变成了一个抽象类,与其将这种错误留待测试甚至留给用户去发现,不如在定义BirdABC/BirdProtocol时就通过静态检查将其揪出来。
abc.ABC的设计思路与C++98的虚类一脉相承,而typing.Protocol提供的这种静态类型检查特性则与Rust的traits十分相似。
下面这个例子将会揭示abc.ABC和typing.Portocol的另一种差异:
1 | from abc import abstractmethod, ABC |
其中fly_abc(bird)会抛出如下警告:
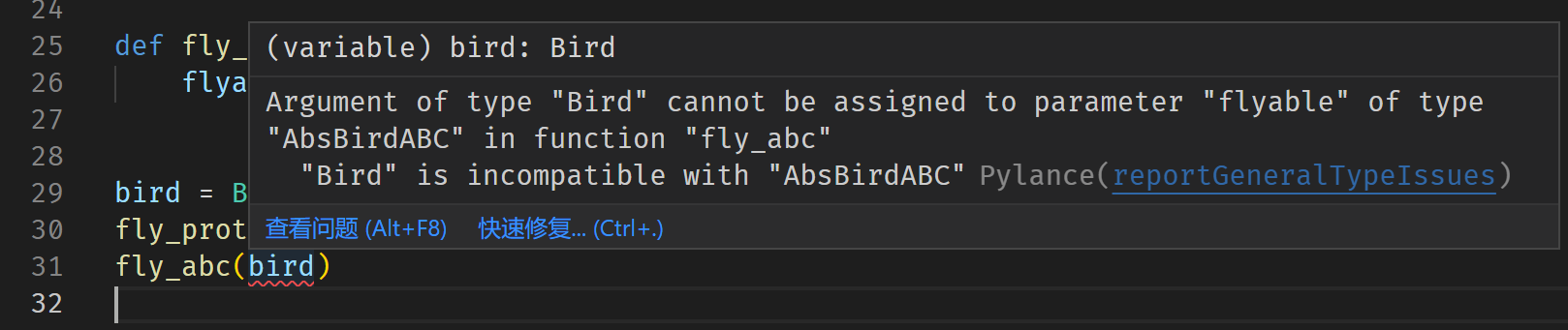
出现该警告的原因是,对于abc.ABC而言,只有显式继承了抽象接口的类才被视为兼容抽象接口的具体类。这里Bird没有继承AbsBirdABC,因此类型检查工具认为Bird与AbsBirdABC不兼容。
但对于typing.Protocol,只要实现了与抽象接口相一致的成员方法与变量就算是兼容了这个抽象接口。即便Bird没有继承AbsBirdProtocol,但类型检查工具认为它们有着完全一致的成员变量、方法名和方法类型注解,因此两者是兼容的。
毫无疑问Protocol的运行机制会更符合人类直觉。
这种从签名一致性出发的兼容性判断正是著名的“鸭子类型”思想的体现——“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子”。
事实上,将typing.Protocol纳入Python标准的PEP 544 - Protocols: Structural
subtyping (static duck typing)正是为了解决PEP 484 - Type
Hints中抽象接口声明不够优雅的问题。在PEP-544之前,下面这种写法会导致静态类型检查抛出警告:
1 | from typing import Iterator, Iterable |
即便Array实现了Iterable所必需的功能,但它仍不被认为是一个Iterable(类比:即便Array实现了“鸭子”所必需的功能,但它仍不被认为是一个“鸭子”)。
为了通过类型检查,我们需要通过继承一个Iterator将Array显式声明为Iterable:
1 | from typing import Iterator, Iterable |
继承Iterator这一步无疑是多此一举,于是PEP-544振臂一呼“我们Python也要有自己的静态鸭子”,Protocol应运而生。现在人人都可以用Protocol静态声明自己的鸭子类型了。
Protocol兼具两大优点:支持静态类型检查、允许用户静态声明自定义的鸭子类型。或许是出于这样的理由,官方建议我们使用Protocol来实现接口的抽象化。
警惕不充分的抽象接口声明
即便静态的抽象接口声明有着这样那样的好处,各种第三方库要充分利用起这一语言特性还需要相当长时间的努力。譬如在PyTorch
1.13中你仍然无法将一个函数的返回值声明为“包含三个通道的Tensor”。在神经网络中,即便两个函数的入参都是Tensor,但很多时候不是随便扔一个Tensor进去都能行得通的,入参往往需要满足各种苛刻的条件。
当抽象接口无法通过类型注解做到充分描述时,就只能使用注释和assert来辅助检查。
例如我在一个自监督学习项目中定义的抽象数据集接口TypeImgSeq,它的__getitem__就拥有非常明确的注释:该接口返回一个长宽不定,通道数为3,数据类型为float32,数据范围在0~1之间的Tensor。
1 | class TypeImgSeq(Protocol): |
然而,即便某个具体实现的__getitem__返回了四通道的Tensor,Python的静态类型检查仍然会认为这个具体实现与TypeImgSeq相兼容。此时我们只能引入额外的assert来辅助查找异常。我习惯将这类检查放在参数的出口而不是入口,即约束前级输出而不是约束后级输入。因为出口异常更方便断点调试。