
译者序
项目要求写一个header-only的高性能图像缩放实现,目标是将任意大小图片缩小至8x8的大小,同时完成灰度化。我不论怎么改进都要比OpenCV-AVX2慢个三倍左右。遂打算写个专栏研究一下当前主流的开源图像缩放实现(OpenCV、Pillow-SIMD等),顺带入门一下算法性能调优。
这篇文章是The Fastest Image Resize Part0的DeepL机翻+人工复核。如有翻译问题可在评论区指出。其作者Alex Karpinsky系Pillow-SIMD的开发者。
前言
我为现代x86架构处理器设计了最快的图像缩放算法实现。我想与大家分享我的经验,希望能给予那些同样从事算法优化的人一些启发。
尽管本文主要面向开发人员,但我还是力求简单明了。不过,我喜欢技术细节,所以我打算多讲一些细节。单篇文章的篇幅似乎不够,所以我会陆续推出更多文章。本篇旨在为您介绍一个大体框架。
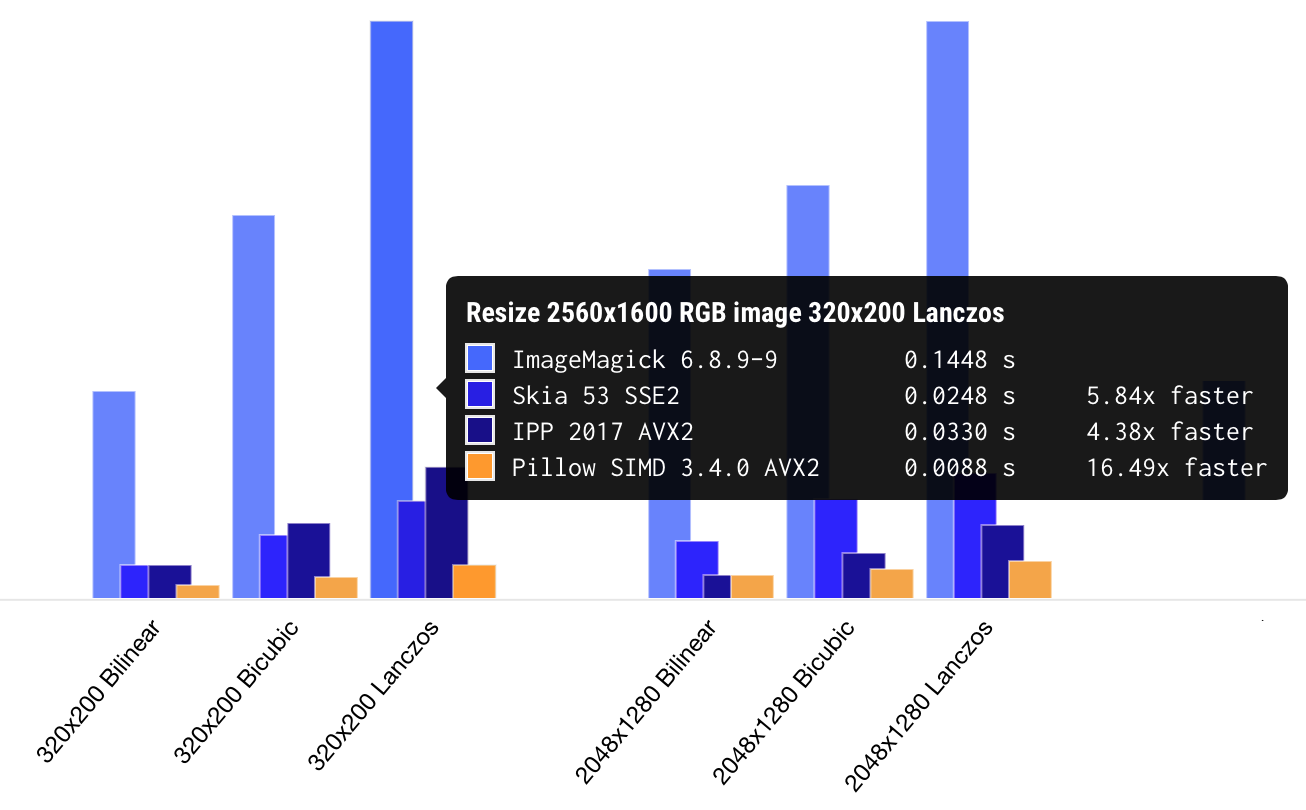
我之所以称它为“最快的缩放实现”,是因为我能找到并测试的所有其他库都比它慢。我创建它并不是为了好玩:我为 Uploadcare工作,图像缩放一直是实时(on-the-fly)图像处理面临的实际问题。经过优化,Uploadcare现在所需要的处理工作负载的服务器比以前减少了六倍。在我创业之初,我们决定开放源代码。我分叉了Uploadcare使用的Python图像处理库Pillow,并将其称为Pillow-SIMD。
目前,Pillow-SIMD缩放图像的平均速度比ImageMagick快15倍。该库的速度甚至比Intel-IPP快,后者是针对各种英特尔架构优化的低层级图像处理构件。这就是问题所在:只有了解运行代码的设备的架构,才能很好地优化代码。
当有人声称自己做出了独一无二的东西时,总会需要测试复核。这也是我工作的一部分,所以你可以随时查看测试结果,提交自己的数据或进行自己的测试。
任务概述
输入条件如下:在未实施任何优化的情况下,将一张iPhone拍摄的照片通过Pillow2.6缩放至200万像素需要约1.37秒。这样,单核心每小时可处理约2500张照片。而在响应式设计时代,你想要更高的效率。
让我们来定义一下什么是“图像缩放任务”。这是一种旨在改变源图像尺寸的操作。在许多情况下,最合适的方法是基于卷积的重采样。它有助于保持源图像的质量,而缺点是该算法的性能较差。
重采样本身是在8位深的RGB像素数组上进行的。所有计算都使用存储在RAM中的数据,因此我们不考虑编解码程序,而是会考虑内存分配和计算操作所需的系数。这很简单,没有从JPEG解码较小图像之类的技巧,也没有算法组合,只是评估卷积重采样计算的速度。
基于卷积的重采样
让我来解释一下卷积(Convolution)在图像缩放算法中的作用。
假设我们正在缩放一幅图像。一开始,输出是一个空矩阵,我们正在计算要放入其单元格中的值。这就是“缩放因子”的作用,它是输入图像尺寸与输出图像尺寸的比值。考虑到该系数,我们总是可以计算出源图像中哪个像素与输出像素“更接近”。最简单的方法就是将最接近(Nearest)的值分配给输出。

看起来很乱,不是吗?
输出质量的显著下降是由于丢失了相当多的源数据(在这些“相邻像素”之间)造成的。而基于卷积的重采样(以下简称“重采样”)是一种计算输出像素的方法,它可以考虑尽可能多的输入像素。它有助于避免局部的几何失真。
此外,重采样具有很强的通用性:它能为各种缩放系数提供可预测的输出质量。在此,请查看对同一图像进行卷积重采样的示例:

结果一般都很好,而性能却不尽人意。
像素是离散的实体,因为我们谈论的是数字图像。这意味着我们使用的是离散卷积。此外,图像是二维的。因此,我们可能想要处理多维卷积,但我们应用的计算是可分离的,因此我们可以使用行列分解(row-column decomposition)。
然后,我们的处理需要两次:每个图像维度一次。这样一来,我们的性能就得到了很好的提升。我们有一行一行的数据和系数集(卷积核)。卷积被定义为两行数据的乘积之和:见下图:
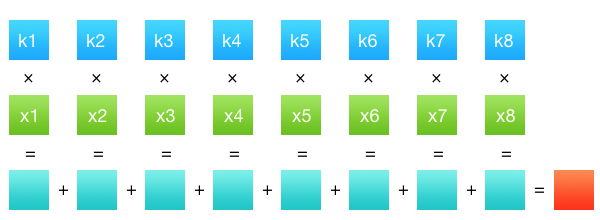
仅此而已。第\(k\)行是源图像单通道的像素值,第\(x\)行是卷积核系数。卷积核有多种形态,对卷积结果(即输出图像的属性)有很大影响。你一般可以在各种图像编辑器中找到插值方法选项,通常有一个下拉菜单,其中有双线性、双立方,或者Lanczos选项。
卷积的作用是为输出图像的每个通道计算像素值。例如,在缩放图像时,我们必须运行卷积\((M * n + M * N) * C\)次。其中,\(M\)和\(N\)是输出图像的宽度和高度,\(n\)是输入图像的高度,\(C\)是通道数。此外,\(M * n\)是中间状态的分辨率。因此,上述表达式适用于我们的两段式(two-pass)方法。
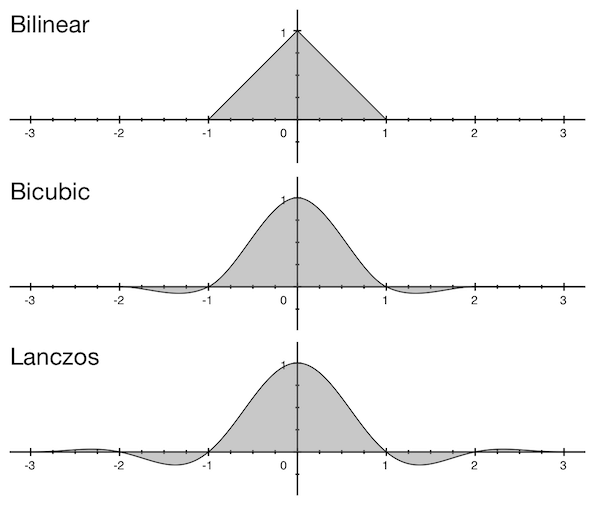
虽然窗口函数有很多,但在图像缩放中经常使用的只有这三种有限函数:双线性、双立方和Lanczos。在通常称为“卷积核宽度”的小半径外,所有值都等于0。下图显示了窗口形状及其宽度:
分解后,我们先处理行,也就是如何填充上述空输出矩阵的单元格。例如,我们需要使用双立方卷积核将宽度为2560像素的图像缩放到宽度为2048像素(缩放系数为1.25)。而我们要计算的是输出的第33个像素的像素值(任意一行都行)。
首先,我们计算出输出像素在输入空间中的位置:\(33 * 1.25 = 41.25\)。缩放时,我们通过将卷积核的宽度乘以缩放因子来调整卷积核的大小。双立方卷积核的宽度为\(2\),这意味着我们将使用\(2 * 1.25 = 2.5\)的大小。
然后,我们取输入行第41个单元格周围的像素:从\(\mathrm{round}(41.25 - 2.5)\)到\(\mathrm{round}(41.25+2.5)\),分别是从第39个像素到第44个像素。得到数据后,我们计算双立方系数并将其与数据卷积。这样,我们就计算出了第33个像素的值,占6个输入单元。由于是逐像素操作,图像内容不会影响性能。
关于Pillow
Pillow是由Alex Clark和Eric Soroos领导的社区维护的Python图像处理库。
我加入Uploadcare团队时,Uploadcare已经在使用这个库了。起初,这似乎很令人惊讶,为什么要使用一个依赖语言的库来完成图像处理这样的关键任务?使用ImageMagick或其他库不是更好吗?目前,我认为Pillow是个好主意,因为Pillow和ImageMagick的性能相当接近,而后者需要我们花费更多的时间和精力来优化缩放算法。
最初,Pillow是从PIL分支而来。而PIL本身并没有使用重采样来调整图像大小。作为ANTIALIAS标志的一部分,该重采样方法在1.1.3版中首次实现。标题暗示了输出质量的提高。
不幸的是,ANTIALIAS的性能很差。这时,我决定去查看源代码,看看能否以某种方式改进操作。结果发现,ANTIALIAS的输出等同于Lanczos卷积核与输入像素进行卷积的结果。正如你已经知道的,Lanczos卷积核相当大,因此速度很慢。
我实施的第一项优化是添加双线性和双立方卷积核。这样就可以使用宽度较小的卷积核,从而在保持“质量”的前提下优化性能。
我的下一步是研究缩放算法的代码。尽管我主要用Python编写代码,但我还是一眼就看出了C代码性能中的一些薄弱环节。在实施了一些优化(我将在下一篇文章中详细介绍)后,性能提升了2.5倍。然后,我开始尝试使用SIMD、纯整数运算、优化循环和分组计算。这项任务完全激起了我的兴趣,我能不断地将涌现的新想法投入实践与测试。
代码一步步变大,速度也越来越快。但要将SIMD代码贡献回原始Pillow代码却相当困难,因为我们的版本采用的是针对x86架构优化,而Pillow本身是一个跨平台库。因此,我最终产生了创建非跨平台分叉的想法:Pillow-SIMD。它的版本与原始Pillow版本完全相同,但在某些操作(如图像缩放)上加入了特定架构的优化。
使用AVX2的最新版Pillow-SIMD缩放图片的速度比原始PIL快15到30倍。同样,它也是我所测试过的图像缩放最快的实现。我甚至制作了这个网页,您可以在上面查看不同程序库的基准测试结果。
我已经说过测试是我工作的一部分,所以让我来告诉你一些测试的方法。我将一张2560×1600像素的图片调整为以下分辨率: 320×200、2048×1280和5478×3424。我还使用了双线性(bil)、双立方(bic)和Lanczos(lzs)卷积核,总共进行9次操作。源图像的尺寸相对较大,因为它不应当被完全塞进L3缓存中。
以下是Pillow 2.6在未进行任何优化的情况下的示例:
1 | Operation Time Bandwidth |
我是这样计算带宽的:如果调整2560×1600图像的大小需要0.2秒,那么带宽等于2560 * 1600 / 0.2 = 20.48 MP/s。
使用Lanczos卷积核,源图像在0.164秒内被调整为320×200大小。听起来不错吧?为什么还要优化呢?其实不然。让我们回想一下,目前智能手机拍摄的照片平均分辨率约为1200万像素。因此,调整照片大小大约需要0.5秒。这就是我在单核上每小时处理2500张照片的起点。
简短的总结
经过优化后,Uploadcare现在可以减少六倍的服务器负载。假设一下,如果我们在全球范围内进行推广,并更改运行全球所有图像缩放操作的代码,我们将节省数以万计的服务器,这至少是一大笔电费。
就我个人而言,我很高兴它成功了。能在英特尔处理器上以比英特尔更快的速度调整图片大小,真是令人兴奋。我们从未停止过研究,我相信它只会越来越好。
另一件让我感到高兴的事情是,Pillow和Pillow-SIMD是真实存在的。它们是任何开发人员都能使用的可投入生产的库。这不仅仅是在Stack Overflow上发布的一些代码,也不仅仅是一些“基本元素”,它们应该像构建工具包一样连接起来才能工作。它甚至不是一个界面阴暗、编译时间长达30分钟的复杂C++库(OpenCV:勿cue)。只需三行命令:安装、导入、加载......砰!“嘿,妈妈,看,我在我的应用程序中使用了世界上最快的图像缩放!”
在下一篇文章中,您将与我一起继续这场优化之旅。